A: In the CORE collection all motifs are reliable.
C-quality motifs have only a single supporting experiment but were nonetheless manually curated and benchmarked. Also, in the
CORE collection, there are only a handful of
D-quality motifs representing a few rare subtypes, which were not rediscovered when updating v11 to v12 and later to v13-v14 but were retained for consistency.
In the sub-collections,
D quality denotes non-benchmarked motifs, e.g. in the ‘
invivo’ sub-collection the
D quality motifs were not tested on ChIP-Seq data.
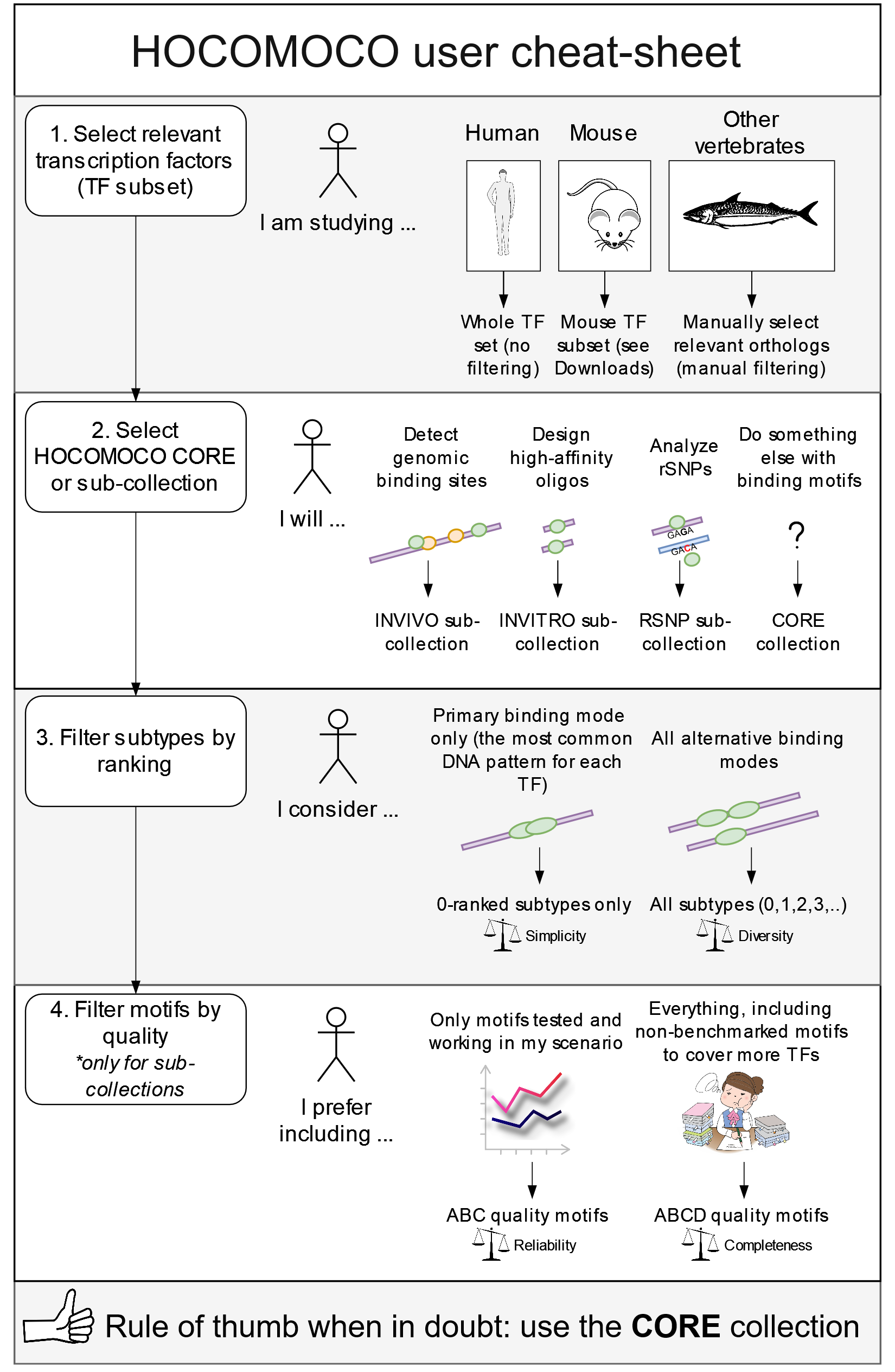
Don't hesitate to consult the
scheme for further hints.
{kind=link}